数据层¶
在数据层,我们使用统一的数据处理器来获取数据、清洗数据和提取特征。
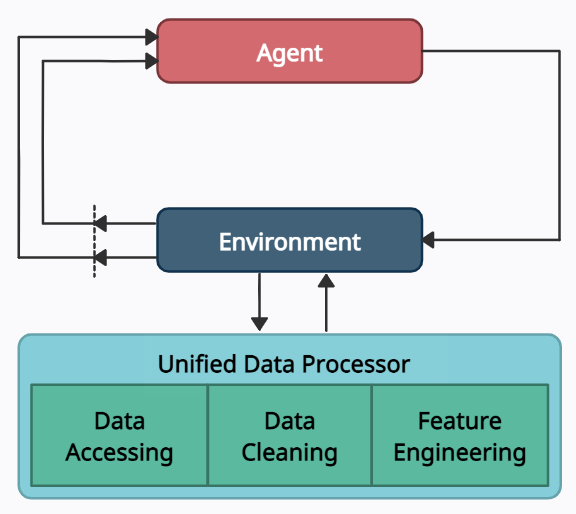
数据获取¶
我们连接不同平台的数据API,并使用FinRL-Meta数据处理器将它们统一起来。用户可以根据开始日期、结束日期、股票列表、时间间隔和 kwargs 从各种来源获取数据。
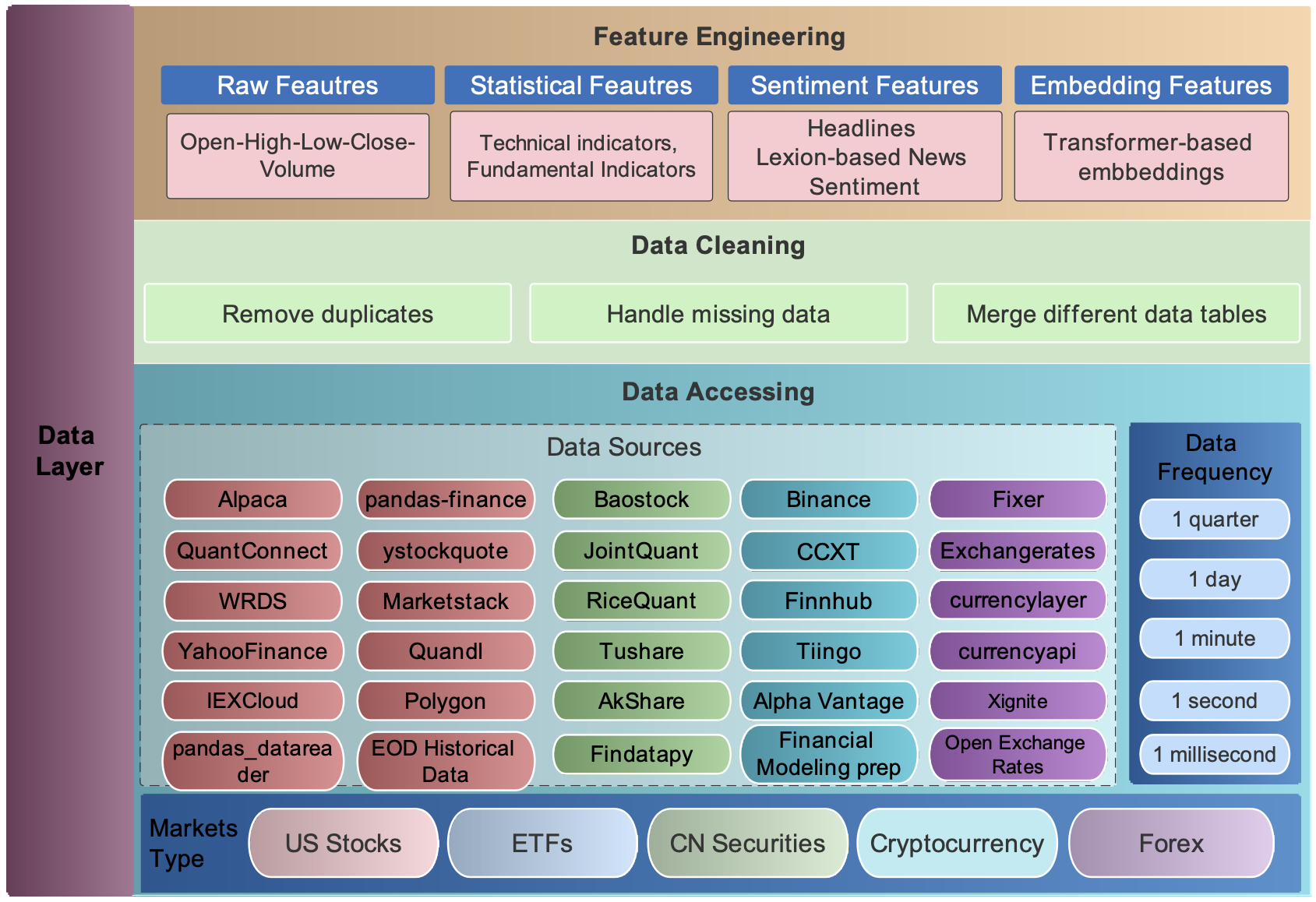
数据清洗¶
从不同数据源获取的原始数据通常格式各异,并在不同程度上存在错误或 NaN 数据(缺失数据),这使得数据清洗非常耗时。在 FinRL-Meta 中,我们将数据清洗过程自动化。
针对不同时间频率的数据,NaN 数据的清洗过程通常不同。对于低频数据,除了少数流动性极低的股票外,少量的 NaN 值通常表示在该时间段内停牌。而对于高频数据,NaN 值普遍存在,通常表示在该时间段内没有交易。考虑到数据效率并缩小仿真与现实之间的差距,我们为这两种情况提供了不同的解决方案。
在低频情况下,我们直接删除包含 NaN 值的行,这反映了模拟交易环境中的停牌情况。然而,在高频情况下直接删除包含 NaN 值的行是不合适的。
在我们的测试中,从 Alpaca 下载了 2021 年 01 月 01 日至 2021 年 05 月 31 日期间道琼斯工业平均指数 30 家公司 1 分钟的 OHLCV 数据,原始数据共有 39736 行。然而,删除包含 NaN 值的行后,只剩下 3361 行。
删除方法的低数据效率是不可接受的。因此,我们采用了一种改进的前向填充方法。我们将开盘价、最高价、最低价、收盘价列填充为最后一个有效的收盘价,并将成交量列填充为 0,这是一种实践中常用的标准方法。
尽管这种填充方法牺牲了模拟环境的真实性,但与显著提高的数据效率相比是可以接受的,尤其是在流动性高的股票下。此外,可以使用买入价、卖出价进一步改进这种填充方法,以缩小仿真与现实之间的差距。
特征工程¶
特征工程是数据层的最后一部分。我们通过在数据处理器中连接 Stockstats 或 TAlib 库来自动化技术指标的计算。支持常见的技术指标,包括移动平均收敛散度 (MACD)、相对强弱指数 (RSI)、平均趋向指数 (ADX) 和商品通道指数 (CCI) 等等。用户还可以快速添加来自其他库的指标,或直接添加用户自定义的特征。
用户可以通过两种方式添加自己的特征:1) 直接编写用户定义的特征提取函数。返回的特征将添加到特征数组中。2) 将特征存储在文件中,并将其移动到指定的文件夹。然后,通过从指定文件中读取来获取这些特征。