概览¶
遵循 OpenAI Gym 的事实标准,我们构建了一个用于数据驱动型金融强化学习的市场环境宇宙,即 FinRL-Meta。我们遵循以下设计原则。
1. 分层结构¶
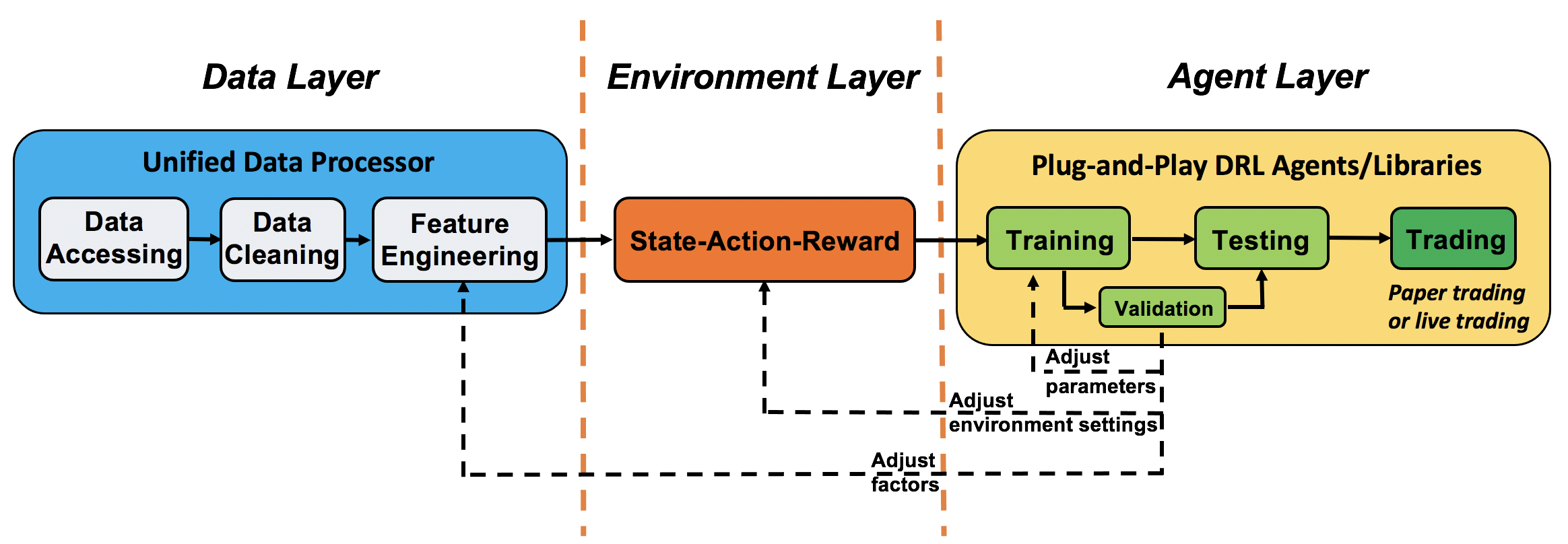
我们采用分层结构来进行金融领域的强化学习 (RL),它由三层组成:数据层、环境层和代理层。每一层都执行其功能且相对独立。主要有以下两个优势:
透明性:各层通过端到端接口交互,实现算法交易的完整工作流程,具有高度可扩展性。
模块化:遵循层与层之间的 API,用户可以轻松自定义功能来替换任何层中的默认功能。
2. DataOps 范式¶
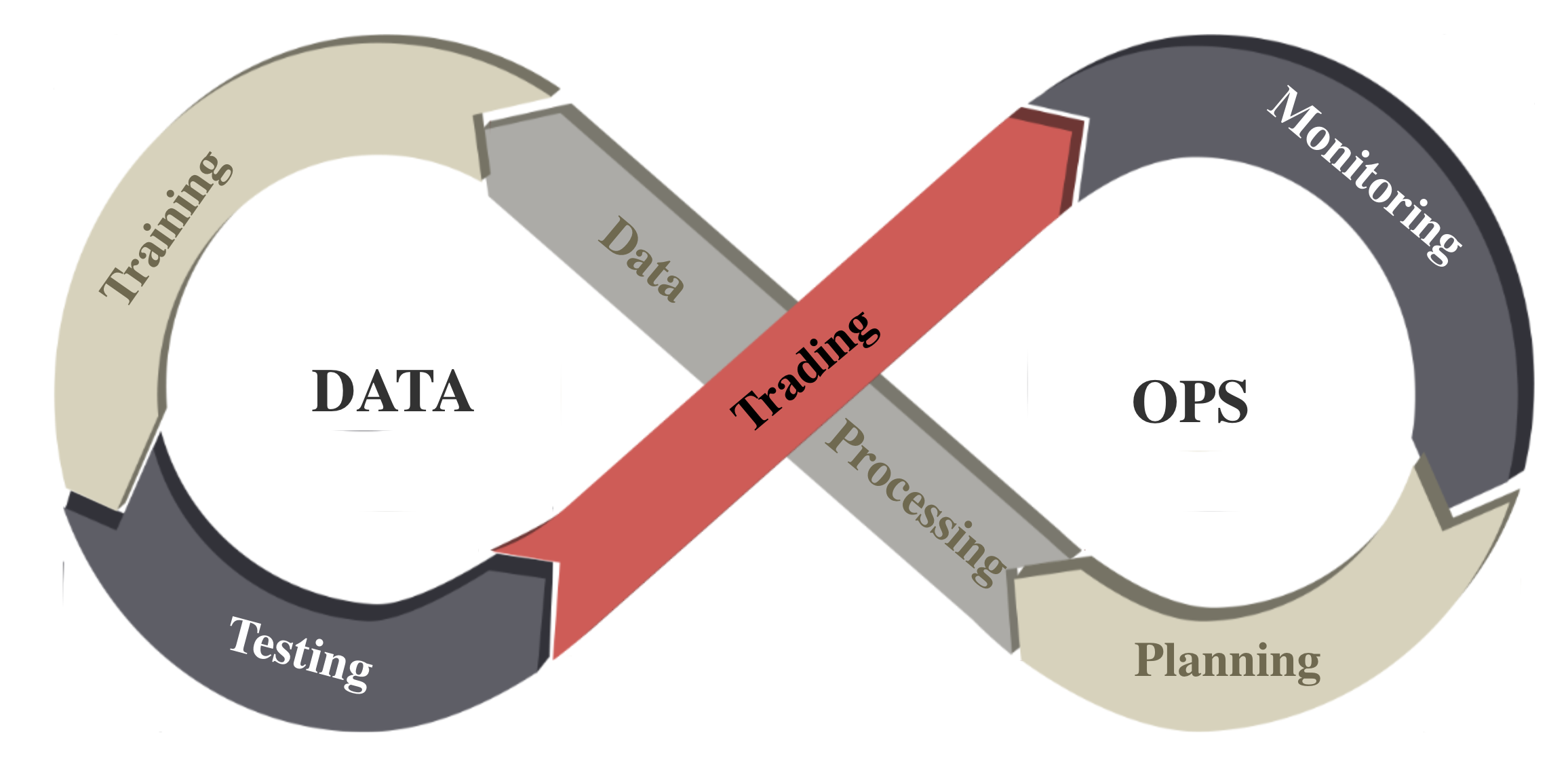
DataOps 范式是一套结合了自动化数据工程和敏捷开发的实践、流程和技术。它有助于减少数据工程的周期时间并提高数据质量。为了处理金融大数据,我们遵循 DataOps 范式并实现了一个自动化流程:
任务规划,例如股票交易、投资组合分配、加密货币交易等。
数据处理,包括数据访问、清洗和特征工程。
训练-测试-交易,深度强化学习 (DRL) 代理参与其中。
性能监控,将深度强化学习代理的性能与一些基准交易策略进行比较。
通过这个流程,我们能够持续生成动态市场数据集。
3. 训练-测试-交易流程:¶
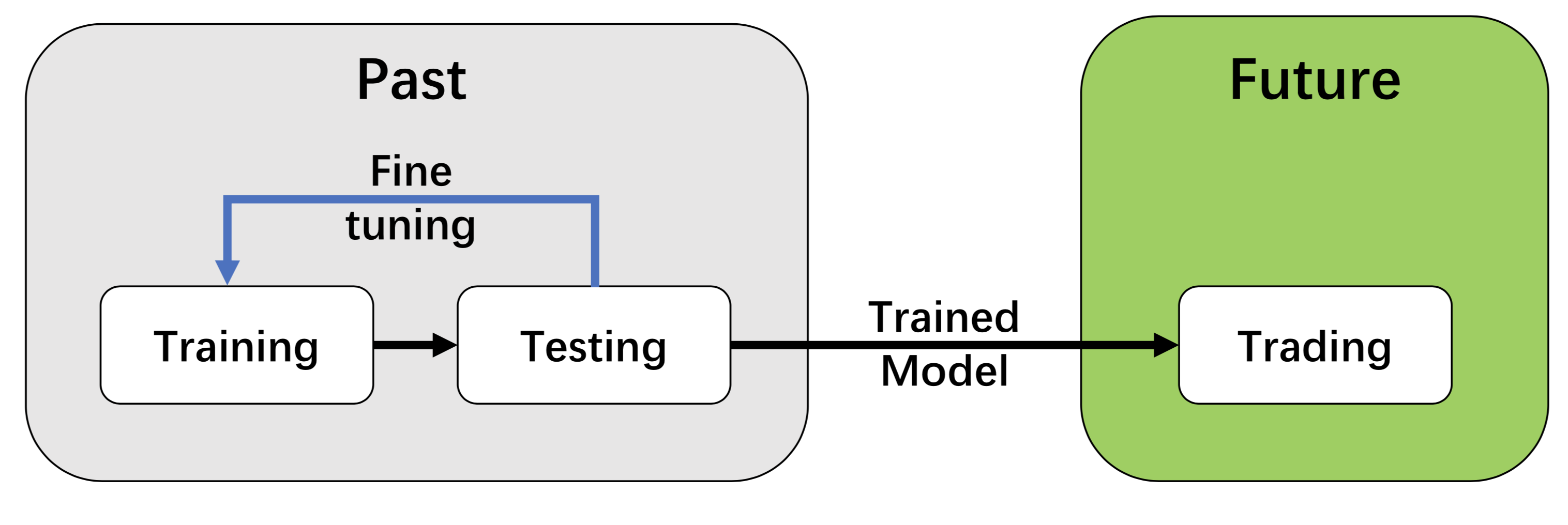
我们采用训练-测试-交易流程,深度强化学习方法遵循标准的端到端流程。深度强化学习代理首先在训练数据集上进行训练,并在测试数据集上进行微调(调整超参数)。然后,对代理进行回测(在历史数据集上),或部署到模拟/实盘交易市场中。
通过分离训练/测试与交易阶段,该流程解决了信息泄露问题,代理在回测或模拟/实盘交易阶段不会看到相应数据。
这种统一的流程也允许对不同算法进行公平比较。
4. 即插即用¶
在开发流程中,我们将市场环境与数据层和代理层分离开来。任何深度强化学习代理都可以直接插入到我们的环境中进行训练和测试。不同的代理可以在相同的基准测试环境上运行,以便进行公平比较。支持多种流行的深度强化学习库,包括 ElegantRL、RLlib 和 SB3。