多股票交易¶
从头开始使用深度强化学习进行股票交易:多股票交易
提示
在 Google Colab 上逐步运行代码。
步骤 1:准备工作¶
步骤 1.1:概述
首先,我想解释一下使用深度强化学习进行多股票交易的逻辑。
我们在本文中始终以道琼斯 30 指数成分股为例,因为它们是最受欢迎的股票。
很多人听到“深度强化学习”这个词就感到害怕,实际上,如果你愿意,你可以把它看作是一个“智能 AI”或“智能股票交易员”或“R2-D2 交易员”,直接使用即可。
假设我们有一个训练有素的 DRL 代理“DRL 交易员”,我们想用它来交易我们投资组合中的多只股票。
假设我们在时间点 t。在时间点 t 的日终,我们将知道道琼斯 30 指数成分股的开盘价、最高价、最低价、收盘价。我们可以利用这些信息计算技术指标,如 MACD、RSI、CCI、ADX。在强化学习中,我们将这些数据或特征称为“状态”。
我们知道我们的投资组合价值 V(t) = 余额 (t) + 股票总市值 (t)。
我们将状态输入到我们训练有素的 DRL 交易员中,交易员将输出一个行动列表,每只股票的行动值在 [-1, 1] 范围内,我们可以将这个值视为交易信号,1 表示强烈的买入信号,-1 表示强烈的卖出信号。
我们计算 k = 行动 * h_max,h_max 是一个预设参数,设定了最大交易股数。因此我们将得到一个交易股数列表。
股票总市值 = 交易股数 * 收盘价 (t)。
更新余额和股数。这些股票的总市值是我们需要在时间点 t 进行交易的资金。更新后的余额 = 余额 (t) − 购买股票支付的金额 + 出售股票收到的金额。更新后的股数 = 持有股数 (t) − 卖出股数 + 买入股数。
因此,我们在时间点 t 的日终(时间 t 的收盘价等于时间 t+1 的开盘价)根据我们的 DRL 交易员的建议采取交易行动。我们希望到时间点 t+1 的日终,这些行动能带来收益。
前进到时间点 t+1,在日终,我们将知道时间点 t+1 的收盘价,股票总市值 (t+1) = 总和 (更新后的股数 * 收盘价 (t+1))。投资组合价值 V(t+1) = 余额 (t+1) + 股票总市值 (t+1)。
因此,从时间点 t 到 t+1,DRL 交易员采取行动的步骤奖励为 r = v(t+1) − v(t)。在训练阶段,奖励可以是正的或负的。但当然,在实际交易中,我们需要正的奖励才能说明我们的 DRL 交易员是有效的。
重复此过程直至终止。
下面是多股票交易的逻辑图和一个用于演示的虚构示例
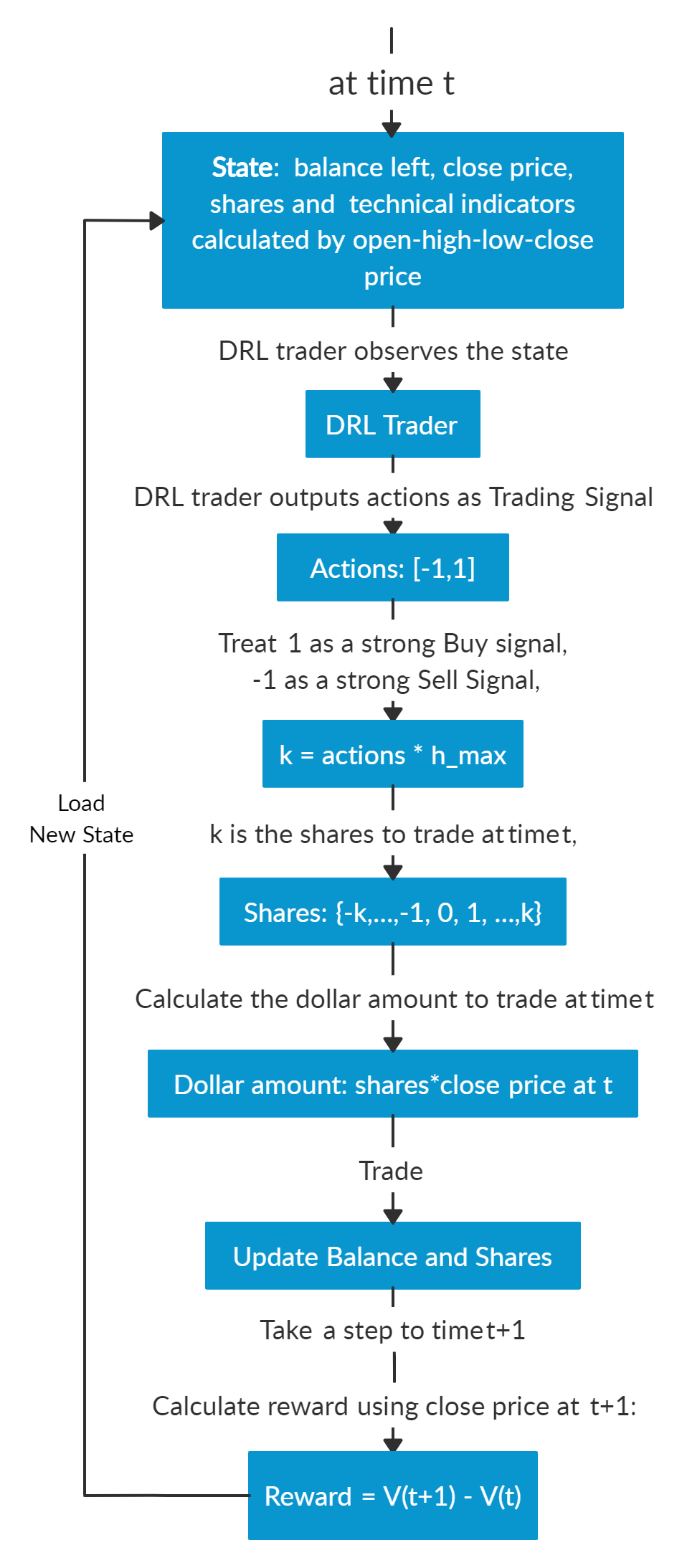

多股票交易与单股票交易不同,因为随着股票数量的增加,数据的维度会增加,强化学习中的状态空间和行动空间会呈指数级增长。因此,稳定性和可复现性在这里至关重要。
我们介绍一个 DRL 库 FinRL,它可以方便初学者接触量化金融并开发自己的股票交易策略。
FinRL 的特点是其可复现性、可扩展性、简单性、适用性和可扩展性。
本文重点介绍我们论文中的一个用例:多股票交易。我们使用一个 Jupyter notebook 来包含所有必要的步骤。
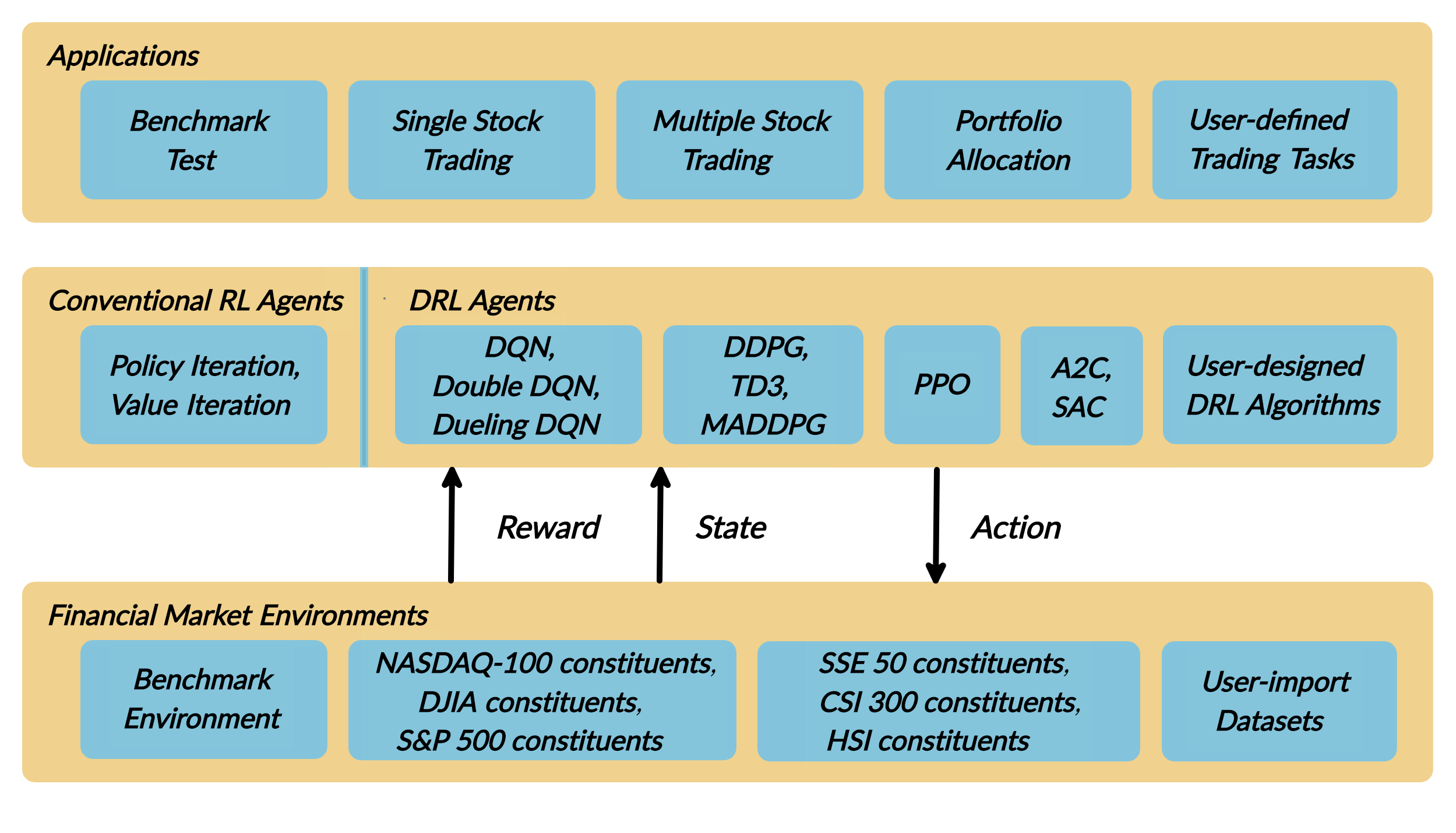
步骤 1.2:问题定义:
本问题旨在设计一个自动化股票交易解决方案。我们将股票交易过程建模为马尔可夫决策过程 (MDP)。然后我们将交易目标表述为一个最大化问题。该算法使用深度强化学习 (DRL) 算法进行训练,强化学习环境的组成部分是
行动 (Action):行动空间描述了代理与环境交互时被允许的行动。通常,a ∈ A 包括三种行动:a ∈ {−1, 0, 1},其中 −1、0、1 分别代表卖出、持有和买入一股股票。此外,一个行动可以针对多股股票。我们使用一个行动空间 {−k, …, −1, 0, 1, …, k},其中 k 表示买入的股数,-k 表示卖出的股数。例如,“买入 10 股 AAPL”或“卖出 10 股 AAPL”分别对应 10 或 −10
奖励函数 (Reward function):r(s, a, s′) 是激励代理学习更好行动的机制。当在状态 s 采取行动 a 并到达新状态 s’ 时,投资组合价值的变化,即 r(s, a, s′) = v′ − v,其中 v′ 和 v 分别代表状态 s′ 和 s 下的投资组合价值
状态 (State):状态空间描述了代理从环境中接收到的观察信息。就像人类交易员在执行交易前需要分析各种信息一样,我们的交易代理也观察许多不同的特征,以便在交互环境中更好地学习。
环境 (Environment):道琼斯 30 指数成分股
本案例研究的股票数据来自雅虎财经 API。数据包含开盘价、最高价、最低价、收盘价和成交量。
步骤 1.3:安装 FinRL:
1## install finrl library
2!pip install git+https://github.com/AI4Finance-LLC/FinRL-Library.git
然后我们导入本次演示所需的包。
步骤 1.4:导入包:
1import pandas as pd
2import numpy as np
3import matplotlib
4import matplotlib.pyplot as plt
5# matplotlib.use('Agg')
6import datetime
7
8%matplotlib inline
9from finrl import config
10from finrl import config_tickers
11from finrl.meta.preprocessor.yahoodownloader import YahooDownloader
12from finrl.meta.preprocessor.preprocessors import FeatureEngineer, data_split
13from finrl.meta.env_stock_trading.env_stocktrading import StockTradingEnv
14from finrl.agents.stablebaselines3.models import DRLAgent
15
16from finrl.plot import backtest_stats, backtest_plot, get_daily_return, get_baseline
17from pprint import pprint
18
19import sys
20sys.path.append("../FinRL-Library")
21
22import itertools
最后,创建用于存储的文件夹。
步骤 1.5:创建文件夹:
1import os
2if not os.path.exists("./" + config.DATA_SAVE_DIR):
3 os.makedirs("./" + config.DATA_SAVE_DIR)
4if not os.path.exists("./" + config.TRAINED_MODEL_DIR):
5 os.makedirs("./" + config.TRAINED_MODEL_DIR)
6if not os.path.exists("./" + config.TENSORBOARD_LOG_DIR):
7 os.makedirs("./" + config.TENSORBOARD_LOG_DIR)
8if not os.path.exists("./" + config.RESULTS_DIR):
9 os.makedirs("./" + config.RESULTS_DIR)
至此,所有准备工作已完成。我们现在可以开始了!
步骤 2:下载数据¶
在训练我们的 DRL 代理之前,我们首先需要获取道琼斯 30 指数股票的历史数据。这里我们使用雅虎财经的数据。雅虎财经是一个提供股票数据、金融新闻、财务报告等的网站。雅虎财经提供的所有数据都是免费的。yfinance 是一个开源库,提供了从雅虎财经下载数据的 API。我们这里将使用这个包来下载数据。
FinRL 使用 YahooDownloader 类来提取数据。
class YahooDownloader:
"""
Provides methods for retrieving daily stock data from Yahoo Finance API
Attributes
----------
start_date : str
start date of the data (modified from config.py)
end_date : str
end date of the data (modified from config.py)
ticker_list : list
a list of stock tickers (modified from config.py)
Methods
-------
fetch_data()
Fetches data from yahoo API
"""
下载数据并将其保存在 pandas DataFrame 中
1 # Download and save the data in a pandas DataFrame:
2 df = YahooDownloader(start_date = '2009-01-01',
3 end_date = '2020-09-30',
4 ticker_list = config_tickers.DOW_30_TICKER).fetch_data()
5
6 print(df.sort_values(['date','tic'],ignore_index=True).head(30))

步骤 3:预处理数据¶
数据预处理是训练高质量机器学习模型的关键步骤。我们需要检查缺失数据并进行特征工程,以便将数据转换为模型可用的状态。
步骤 3.1:检查缺失数据
1# check missing data
2dow_30.isnull().values.any()
步骤 3.2:添加技术指标
在实际交易中,需要考虑各种信息,例如历史股票价格、当前持有股数、技术指标等。在本文中,我们演示了两个趋势跟踪技术指标:MACD 和 RSI。
1def add_technical_indicator(df):
2 """
3 calcualte technical indicators
4 use stockstats package to add technical inidactors
5 :param data: (df) pandas dataframe
6 :return: (df) pandas dataframe
7 """
8 stock = Sdf.retype(df.copy())
9 stock['close'] = stock['adjcp']
10 unique_ticker = stock.tic.unique()
11
12 macd = pd.DataFrame()
13 rsi = pd.DataFrame()
14
15 #temp = stock[stock.tic == unique_ticker[0]]['macd']
16 for i in range(len(unique_ticker)):
17 ## macd
18 temp_macd = stock[stock.tic == unique_ticker[i]]['macd']
19 temp_macd = pd.DataFrame(temp_macd)
20 macd = macd.append(temp_macd, ignore_index=True)
21 ## rsi
22 temp_rsi = stock[stock.tic == unique_ticker[i]]['rsi_30']
23 temp_rsi = pd.DataFrame(temp_rsi)
24 rsi = rsi.append(temp_rsi, ignore_index=True)
25
26 df['macd'] = macd
27 df['rsi'] = rsi
28 return df
步骤 3.3:添加市场湍流指数
风险厌恶反映了投资者是否会选择保全资本。它也影响着个人在面对不同市场波动水平时的交易策略。
为了控制最坏情况下的风险,例如 2007-2008 年的金融危机,FinRL 采用了衡量极端资产价格波动的金融湍流指数。
1def add_turbulence(df):
2 """
3 add turbulence index from a precalcualted dataframe
4 :param data: (df) pandas dataframe
5 :return: (df) pandas dataframe
6 """
7 turbulence_index = calcualte_turbulence(df)
8 df = df.merge(turbulence_index, on='datadate')
9 df = df.sort_values(['datadate','tic']).reset_index(drop=True)
10 return df
11
12
13
14def calcualte_turbulence(df):
15 """calculate turbulence index based on dow 30"""
16 # can add other market assets
17
18 df_price_pivot=df.pivot(index='datadate', columns='tic', values='adjcp')
19 unique_date = df.datadate.unique()
20 # start after a year
21 start = 252
22 turbulence_index = [0]*start
23 #turbulence_index = [0]
24 count=0
25 for i in range(start,len(unique_date)):
26 current_price = df_price_pivot[df_price_pivot.index == unique_date[i]]
27 hist_price = df_price_pivot[[n in unique_date[0:i] for n in df_price_pivot.index ]]
28 cov_temp = hist_price.cov()
29 current_temp=(current_price - np.mean(hist_price,axis=0))
30 temp = current_temp.values.dot(np.linalg.inv(cov_temp)).dot(current_temp.values.T)
31 if temp>0:
32 count+=1
33 if count>2:
34 turbulence_temp = temp[0][0]
35 else:
36 #avoid large outlier because of the calculation just begins
37 turbulence_temp=0
38 else:
39 turbulence_temp=0
40 turbulence_index.append(turbulence_temp)
41
42
43 turbulence_index = pd.DataFrame({'datadate':df_price_pivot.index,
44 'turbulence':turbulence_index})
45 return turbulence_index
步骤 3.4:特征工程
FinRL 使用 FeatureEngineer 类来预处理数据。
执行特征工程
1 # Perform Feature Engineering:
2 df = FeatureEngineer(df.copy(),
3 use_technical_indicator=True,
4 tech_indicator_list = config.INDICATORS,
5 use_turbulence=True,
6 user_defined_feature = False).preprocess_data()

步骤 4:设计环境¶
考虑到自动化股票交易任务的随机性和交互性,将金融任务建模为马尔可夫决策过程 (MDP) 问题。训练过程包括观察股票价格变化、采取行动和计算奖励,以便代理相应地调整其策略。通过与环境交互,交易代理将随着时间的推移推导出最大化奖励的交易策略。
我们的交易环境基于 OpenAI Gym 框架,根据时间驱动模拟的原理,利用真实市场数据模拟实时股票市场。
行动空间描述了代理与环境交互时允许的行动。通常,行动 a 包括三种行动:{-1, 0, 1},其中 -1、0、1 分别代表卖出、持有和买入一股股票。此外,一个行动可以针对多股股票。我们使用行动空间 {-k,…,-1, 0, 1, …, k},其中 k 表示买入的股数,-k 表示卖出的股数。例如,“买入 10 股 AAPL”或“卖出 10 股 AAPL”分别对应 10 或 -10。连续行动空间需要归一化到 [-1, 1],因为策略是在高斯分布上定义的,这需要归一化和对称。
步骤 4.1:训练环境
1## Environment for Training
2import numpy as np
3import pandas as pd
4from gym.utils import seeding
5import gym
6from gym import spaces
7import matplotlib
8matplotlib.use('Agg')
9import matplotlib.pyplot as plt
10
11# shares normalization factor
12# 100 shares per trade
13HMAX_NORMALIZE = 100
14# initial amount of money we have in our account
15INITIAL_ACCOUNT_BALANCE=1000000
16# total number of stocks in our portfolio
17STOCK_DIM = 30
18# transaction fee: 1/1000 reasonable percentage
19TRANSACTION_FEE_PERCENT = 0.001
20
21REWARD_SCALING = 1e-4
22
23
24class StockEnvTrain(gym.Env):
25 """A stock trading environment for OpenAI gym"""
26 metadata = {'render.modes': ['human']}
27
28 def __init__(self, df,day = 0):
29 #super(StockEnv, self).__init__()
30 self.day = day
31 self.df = df
32
33 # action_space normalization and shape is STOCK_DIM
34 self.action_space = spaces.Box(low = -1, high = 1,shape = (STOCK_DIM,))
35 # Shape = 181: [Current Balance]+[prices 1-30]+[owned shares 1-30]
36 # +[macd 1-30]+ [rsi 1-30] + [cci 1-30] + [adx 1-30]
37 self.observation_space = spaces.Box(low=0, high=np.inf, shape = (121,))
38 # load data from a pandas dataframe
39 self.data = self.df.loc[self.day,:]
40 self.terminal = False
41 # initalize state
42 self.state = [INITIAL_ACCOUNT_BALANCE] + \
43 self.data.adjcp.values.tolist() + \
44 [0]*STOCK_DIM + \
45 self.data.macd.values.tolist() + \
46 self.data.rsi.values.tolist()
47 #self.data.cci.values.tolist() + \
48 #self.data.adx.values.tolist()
49 # initialize reward
50 self.reward = 0
51 self.cost = 0
52 # memorize all the total balance change
53 self.asset_memory = [INITIAL_ACCOUNT_BALANCE]
54 self.rewards_memory = []
55 self.trades = 0
56 self._seed()
57
58 def _sell_stock(self, index, action):
59 # perform sell action based on the sign of the action
60 if self.state[index+STOCK_DIM+1] > 0:
61 #update balance
62 self.state[0] += \
63 self.state[index+1]*min(abs(action),self.state[index+STOCK_DIM+1]) * \
64 (1- TRANSACTION_FEE_PERCENT)
65
66 self.state[index+STOCK_DIM+1] -= min(abs(action), self.state[index+STOCK_DIM+1])
67 self.cost +=self.state[index+1]*min(abs(action),self.state[index+STOCK_DIM+1]) * \
68 TRANSACTION_FEE_PERCENT
69 self.trades+=1
70 else:
71 pass
72
73 def _buy_stock(self, index, action):
74 # perform buy action based on the sign of the action
75 available_amount = self.state[0] // self.state[index+1]
76 # print('available_amount:{}'.format(available_amount))
77
78 #update balance
79 self.state[0] -= self.state[index+1]*min(available_amount, action)* \
80 (1+ TRANSACTION_FEE_PERCENT)
81
82 self.state[index+STOCK_DIM+1] += min(available_amount, action)
83
84 self.cost+=self.state[index+1]*min(available_amount, action)* \
85 TRANSACTION_FEE_PERCENT
86 self.trades+=1
87
88 def step(self, actions):
89 # print(self.day)
90 self.terminal = self.day >= len(self.df.index.unique())-1
91 # print(actions)
92
93 if self.terminal:
94 plt.plot(self.asset_memory,'r')
95 plt.savefig('account_value_train.png')
96 plt.close()
97 end_total_asset = self.state[0]+ \
98 sum(np.array(self.state[1:(STOCK_DIM+1)])*np.array(self.state[(STOCK_DIM+1):(STOCK_DIM*2+1)]))
99 print("previous_total_asset:{}".format(self.asset_memory[0]))
100
101 print("end_total_asset:{}".format(end_total_asset))
102 df_total_value = pd.DataFrame(self.asset_memory)
103 df_total_value.to_csv('account_value_train.csv')
104 print("total_reward:{}".format(self.state[0]+sum(np.array(self.state[1:(STOCK_DIM+1)])*np.array(self.state[(STOCK_DIM+1):61]))- INITIAL_ACCOUNT_BALANCE ))
105 print("total_cost: ", self.cost)
106 print("total_trades: ", self.trades)
107 df_total_value.columns = ['account_value']
108 df_total_value['daily_return']=df_total_value.pct_change(1)
109 sharpe = (252**0.5)*df_total_value['daily_return'].mean()/ \
110 df_total_value['daily_return'].std()
111 print("Sharpe: ",sharpe)
112 print("=================================")
113 df_rewards = pd.DataFrame(self.rewards_memory)
114 df_rewards.to_csv('account_rewards_train.csv')
115
116 return self.state, self.reward, self.terminal,{}
117
118 else:
119 actions = actions * HMAX_NORMALIZE
120
121 begin_total_asset = self.state[0]+ \
122 sum(np.array(self.state[1:(STOCK_DIM+1)])*np.array(self.state[(STOCK_DIM+1):61]))
123 #print("begin_total_asset:{}".format(begin_total_asset))
124
125 argsort_actions = np.argsort(actions)
126
127 sell_index = argsort_actions[:np.where(actions < 0)[0].shape[0]]
128 buy_index = argsort_actions[::-1][:np.where(actions > 0)[0].shape[0]]
129
130 for index in sell_index:
131 # print('take sell action'.format(actions[index]))
132 self._sell_stock(index, actions[index])
133
134 for index in buy_index:
135 # print('take buy action: {}'.format(actions[index]))
136 self._buy_stock(index, actions[index])
137
138 self.day += 1
139 self.data = self.df.loc[self.day,:]
140 #load next state
141 # print("stock_shares:{}".format(self.state[29:]))
142 self.state = [self.state[0]] + \
143 self.data.adjcp.values.tolist() + \
144 list(self.state[(STOCK_DIM+1):61]) + \
145 self.data.macd.values.tolist() + \
146 self.data.rsi.values.tolist()
147
148 end_total_asset = self.state[0]+ \
149 sum(np.array(self.state[1:(STOCK_DIM+1)])*np.array(self.state[(STOCK_DIM+1):61]))
150
151 #print("end_total_asset:{}".format(end_total_asset))
152
153 self.reward = end_total_asset - begin_total_asset
154 self.rewards_memory.append(self.reward)
155
156 self.reward = self.reward * REWARD_SCALING
157 # print("step_reward:{}".format(self.reward))
158
159 self.asset_memory.append(end_total_asset)
160
161
162 return self.state, self.reward, self.terminal, {}
163
164 def reset(self):
165 self.asset_memory = [INITIAL_ACCOUNT_BALANCE]
166 self.day = 0
167 self.data = self.df.loc[self.day,:]
168 self.cost = 0
169 self.trades = 0
170 self.terminal = False
171 self.rewards_memory = []
172 #initiate state
173 self.state = [INITIAL_ACCOUNT_BALANCE] + \
174 self.data.adjcp.values.tolist() + \
175 [0]*STOCK_DIM + \
176 self.data.macd.values.tolist() + \
177 self.data.rsi.values.tolist()
178 return self.state
179
180 def render(self, mode='human'):
181 return self.state
182
183 def _seed(self, seed=None):
184 self.np_random, seed = seeding.np_random(seed)
185 return [seed]
步骤 4.2:交易环境
1## Environment for Trading
2import numpy as np
3import pandas as pd
4from gym.utils import seeding
5import gym
6from gym import spaces
7import matplotlib
8matplotlib.use('Agg')
9import matplotlib.pyplot as plt
10
11# shares normalization factor
12# 100 shares per trade
13HMAX_NORMALIZE = 100
14# initial amount of money we have in our account
15INITIAL_ACCOUNT_BALANCE=1000000
16# total number of stocks in our portfolio
17STOCK_DIM = 30
18# transaction fee: 1/1000 reasonable percentage
19TRANSACTION_FEE_PERCENT = 0.001
20
21# turbulence index: 90-150 reasonable threshold
22#TURBULENCE_THRESHOLD = 140
23REWARD_SCALING = 1e-4
24
25class StockEnvTrade(gym.Env):
26 """A stock trading environment for OpenAI gym"""
27 metadata = {'render.modes': ['human']}
28
29 def __init__(self, df,day = 0,turbulence_threshold=140):
30 #super(StockEnv, self).__init__()
31 #money = 10 , scope = 1
32 self.day = day
33 self.df = df
34 # action_space normalization and shape is STOCK_DIM
35 self.action_space = spaces.Box(low = -1, high = 1,shape = (STOCK_DIM,))
36 # Shape = 181: [Current Balance]+[prices 1-30]+[owned shares 1-30]
37 # +[macd 1-30]+ [rsi 1-30] + [cci 1-30] + [adx 1-30]
38 self.observation_space = spaces.Box(low=0, high=np.inf, shape = (121,))
39 # load data from a pandas dataframe
40 self.data = self.df.loc[self.day,:]
41 self.terminal = False
42 self.turbulence_threshold = turbulence_threshold
43 # initalize state
44 self.state = [INITIAL_ACCOUNT_BALANCE] + \
45 self.data.adjcp.values.tolist() + \
46 [0]*STOCK_DIM + \
47 self.data.macd.values.tolist() + \
48 self.data.rsi.values.tolist()
49
50 # initialize reward
51 self.reward = 0
52 self.turbulence = 0
53 self.cost = 0
54 self.trades = 0
55 # memorize all the total balance change
56 self.asset_memory = [INITIAL_ACCOUNT_BALANCE]
57 self.rewards_memory = []
58 self.actions_memory=[]
59 self.date_memory=[]
60 self._seed()
61
62
63 def _sell_stock(self, index, action):
64 # perform sell action based on the sign of the action
65 if self.turbulence<self.turbulence_threshold:
66 if self.state[index+STOCK_DIM+1] > 0:
67 #update balance
68 self.state[0] += \
69 self.state[index+1]*min(abs(action),self.state[index+STOCK_DIM+1]) * \
70 (1- TRANSACTION_FEE_PERCENT)
71
72 self.state[index+STOCK_DIM+1] -= min(abs(action), self.state[index+STOCK_DIM+1])
73 self.cost +=self.state[index+1]*min(abs(action),self.state[index+STOCK_DIM+1]) * \
74 TRANSACTION_FEE_PERCENT
75 self.trades+=1
76 else:
77 pass
78 else:
79 # if turbulence goes over threshold, just clear out all positions
80 if self.state[index+STOCK_DIM+1] > 0:
81 #update balance
82 self.state[0] += self.state[index+1]*self.state[index+STOCK_DIM+1]* \
83 (1- TRANSACTION_FEE_PERCENT)
84 self.state[index+STOCK_DIM+1] =0
85 self.cost += self.state[index+1]*self.state[index+STOCK_DIM+1]* \
86 TRANSACTION_FEE_PERCENT
87 self.trades+=1
88 else:
89 pass
90
91 def _buy_stock(self, index, action):
92 # perform buy action based on the sign of the action
93 if self.turbulence< self.turbulence_threshold:
94 available_amount = self.state[0] // self.state[index+1]
95 # print('available_amount:{}'.format(available_amount))
96
97 #update balance
98 self.state[0] -= self.state[index+1]*min(available_amount, action)* \
99 (1+ TRANSACTION_FEE_PERCENT)
100
101 self.state[index+STOCK_DIM+1] += min(available_amount, action)
102
103 self.cost+=self.state[index+1]*min(available_amount, action)* \
104 TRANSACTION_FEE_PERCENT
105 self.trades+=1
106 else:
107 # if turbulence goes over threshold, just stop buying
108 pass
109
110 def step(self, actions):
111 # print(self.day)
112 self.terminal = self.day >= len(self.df.index.unique())-1
113 # print(actions)
114
115 if self.terminal:
116 plt.plot(self.asset_memory,'r')
117 plt.savefig('account_value_trade.png')
118 plt.close()
119
120 df_date = pd.DataFrame(self.date_memory)
121 df_date.columns = ['datadate']
122 df_date.to_csv('df_date.csv')
123
124
125 df_actions = pd.DataFrame(self.actions_memory)
126 df_actions.columns = self.data.tic.values
127 df_actions.index = df_date.datadate
128 df_actions.to_csv('df_actions.csv')
129
130 df_total_value = pd.DataFrame(self.asset_memory)
131 df_total_value.to_csv('account_value_trade.csv')
132 end_total_asset = self.state[0]+ \
133 sum(np.array(self.state[1:(STOCK_DIM+1)])*np.array(self.state[(STOCK_DIM+1):(STOCK_DIM*2+1)]))
134 print("previous_total_asset:{}".format(self.asset_memory[0]))
135
136 print("end_total_asset:{}".format(end_total_asset))
137 print("total_reward:{}".format(self.state[0]+sum(np.array(self.state[1:(STOCK_DIM+1)])*np.array(self.state[(STOCK_DIM+1):61]))- self.asset_memory[0] ))
138 print("total_cost: ", self.cost)
139 print("total trades: ", self.trades)
140
141 df_total_value.columns = ['account_value']
142 df_total_value['daily_return']=df_total_value.pct_change(1)
143 sharpe = (252**0.5)*df_total_value['daily_return'].mean()/ \
144 df_total_value['daily_return'].std()
145 print("Sharpe: ",sharpe)
146
147 df_rewards = pd.DataFrame(self.rewards_memory)
148 df_rewards.to_csv('account_rewards_trade.csv')
149
150 # print('total asset: {}'.format(self.state[0]+ sum(np.array(self.state[1:29])*np.array(self.state[29:]))))
151 #with open('obs.pkl', 'wb') as f:
152 # pickle.dump(self.state, f)
153
154 return self.state, self.reward, self.terminal,{}
155
156 else:
157 # print(np.array(self.state[1:29]))
158 self.date_memory.append(self.data.datadate.unique())
159
160 #print(self.data)
161 actions = actions * HMAX_NORMALIZE
162 if self.turbulence>=self.turbulence_threshold:
163 actions=np.array([-HMAX_NORMALIZE]*STOCK_DIM)
164 self.actions_memory.append(actions)
165
166 #actions = (actions.astype(int))
167
168 begin_total_asset = self.state[0]+ \
169 sum(np.array(self.state[1:(STOCK_DIM+1)])*np.array(self.state[(STOCK_DIM+1):(STOCK_DIM*2+1)]))
170 #print("begin_total_asset:{}".format(begin_total_asset))
171
172 argsort_actions = np.argsort(actions)
173 #print(argsort_actions)
174
175 sell_index = argsort_actions[:np.where(actions < 0)[0].shape[0]]
176 buy_index = argsort_actions[::-1][:np.where(actions > 0)[0].shape[0]]
177
178 for index in sell_index:
179 # print('take sell action'.format(actions[index]))
180 self._sell_stock(index, actions[index])
181
182 for index in buy_index:
183 # print('take buy action: {}'.format(actions[index]))
184 self._buy_stock(index, actions[index])
185
186 self.day += 1
187 self.data = self.df.loc[self.day,:]
188 self.turbulence = self.data['turbulence'].values[0]
189 #print(self.turbulence)
190 #load next state
191 # print("stock_shares:{}".format(self.state[29:]))
192 self.state = [self.state[0]] + \
193 self.data.adjcp.values.tolist() + \
194 list(self.state[(STOCK_DIM+1):(STOCK_DIM*2+1)]) + \
195 self.data.macd.values.tolist() + \
196 self.data.rsi.values.tolist()
197
198 end_total_asset = self.state[0]+ \
199 sum(np.array(self.state[1:(STOCK_DIM+1)])*np.array(self.state[(STOCK_DIM+1):(STOCK_DIM*2+1)]))
200
201 #print("end_total_asset:{}".format(end_total_asset))
202
203 self.reward = end_total_asset - begin_total_asset
204 self.rewards_memory.append(self.reward)
205
206 self.reward = self.reward * REWARD_SCALING
207
208 self.asset_memory.append(end_total_asset)
209
210 return self.state, self.reward, self.terminal, {}
211
212 def reset(self):
213 self.asset_memory = [INITIAL_ACCOUNT_BALANCE]
214 self.day = 0
215 self.data = self.df.loc[self.day,:]
216 self.turbulence = 0
217 self.cost = 0
218 self.trades = 0
219 self.terminal = False
220 #self.iteration=self.iteration
221 self.rewards_memory = []
222 self.actions_memory=[]
223 self.date_memory=[]
224 #initiate state
225 self.state = [INITIAL_ACCOUNT_BALANCE] + \
226 self.data.adjcp.values.tolist() + \
227 [0]*STOCK_DIM + \
228 self.data.macd.values.tolist() + \
229 self.data.rsi.values.tolist()
230
231 return self.state
232
233 def render(self, mode='human',close=False):
234 return self.state
235
236
237 def _seed(self, seed=None):
238 self.np_random, seed = seeding.np_random(seed)
239 return [seed]
步骤 5:实现 DRL 算法¶
DRL 算法的实现基于 OpenAI Baselines 和 Stable Baselines。Stable Baselines 是 OpenAI Baselines 的一个分支,进行了主要的结构重构和代码清理。
步骤 5.1:训练数据划分:2009-01-01 至 2018-12-31
1def data_split(df,start,end):
2 """
3 split the dataset into training or testing using date
4 :param data: (df) pandas dataframe, start, end
5 :return: (df) pandas dataframe
6 """
7 data = df[(df.datadate >= start) & (df.datadate < end)]
8 data=data.sort_values(['datadate','tic'],ignore_index=True)
9 data.index = data.datadate.factorize()[0]
10 return data
步骤 5.2:模型训练:DDPG
1## tensorboard --logdir ./multiple_stock_tensorboard/
2# add noise to the action in DDPG helps in learning for better exploration
3n_actions = env_train.action_space.shape[-1]
4param_noise = None
5action_noise = OrnsteinUhlenbeckActionNoise(mean=np.zeros(n_actions), sigma=float(0.5) * np.ones(n_actions))
6
7# model settings
8model_ddpg = DDPG('MlpPolicy',
9 env_train,
10 batch_size=64,
11 buffer_size=100000,
12 param_noise=param_noise,
13 action_noise=action_noise,
14 verbose=0,
15 tensorboard_log="./multiple_stock_tensorboard/")
16
17## 250k timesteps: took about 20 mins to finish
18model_ddpg.learn(total_timesteps=250000, tb_log_name="DDPG_run_1")
步骤 5.3:交易
假设我们在 2019-01-01 拥有 $1,000,000 的初始资金。我们使用 DDPG 模型交易道琼斯 30 指数股票。
步骤 5.4:设置市场湍流阈值
将市场湍流阈值设置为样本内市场湍流数据的 99% 分位数,如果当前市场湍流指数大于该阈值,则我们认为当前市场处于波动状态
1insample_turbulence = dow_30[(dow_30.datadate<'2019-01-01') & (dow_30.datadate>='2009-01-01')]
2insample_turbulence = insample_turbulence.drop_duplicates(subset=['datadate'])
步骤 5.5:准备测试数据和环境
1# test data
2test = data_split(dow_30, start='2019-01-01', end='2020-10-30')
3# testing env
4env_test = DummyVecEnv([lambda: StockEnvTrade(test, turbulence_threshold=insample_turbulence_threshold)])
5obs_test = env_test.reset()
步骤 5.6:预测
1def DRL_prediction(model, data, env, obs):
2 print("==============Model Prediction===========")
3 for i in range(len(data.index.unique())):
4 action, _states = model.predict(obs)
5 obs, rewards, dones, info = env.step(action)
6 env.render()
步骤 6:回测我们的策略¶
为简单起见,在本文中,我们仅手动计算夏普比率和年化收益。
1def backtest_strat(df):
2 strategy_ret= df.copy()
3 strategy_ret['Date'] = pd.to_datetime(strategy_ret['Date'])
4 strategy_ret.set_index('Date', drop = False, inplace = True)
5 strategy_ret.index = strategy_ret.index.tz_localize('UTC')
6 del strategy_ret['Date']
7 ts = pd.Series(strategy_ret['daily_return'].values, index=strategy_ret.index)
8 return ts
步骤 6.1:道琼斯工业平均指数
1def get_buy_and_hold_sharpe(test):
2 test['daily_return']=test['adjcp'].pct_change(1)
3 sharpe = (252**0.5)*test['daily_return'].mean()/ \
4 test['daily_return'].std()
5 annual_return = ((test['daily_return'].mean()+1)**252-1)*100
6 print("annual return: ", annual_return)
7
8 print("sharpe ratio: ", sharpe)
9 #return sharpe
步骤 6.2:我们的 DRL 交易策略
1def get_daily_return(df):
2 df['daily_return']=df.account_value.pct_change(1)
3 #df=df.dropna()
4 sharpe = (252**0.5)*df['daily_return'].mean()/ \
5 df['daily_return'].std()
6
7 annual_return = ((df['daily_return'].mean()+1)**252-1)*100
8 print("annual return: ", annual_return)
9 print("sharpe ratio: ", sharpe)
10 return df
步骤 6.3:使用 Quantopian pyfolio 绘制结果
回测在评估交易策略的性能方面起着关键作用。自动化回测工具更受欢迎,因为它减少了人为错误。我们通常使用 Quantopian pyfolio 包来回测我们的交易策略。它易于使用,包含各种单独的图表,提供交易策略性能的全面视图。
1%matplotlib inline
2with pyfolio.plotting.plotting_context(font_scale=1.1):
3 pyfolio.create_full_tear_sheet(returns = DRL_strat,
4 benchmark_rets=dow_strat, set_context=False)