2. DRL Agent¶
FinRL 集成了 ElegantRL、Stable Baseline 3 和 RLlib 中经过微调的标准 DRL 算法。ElegantRL 是一个由 AI4Finance 维护的可扩展、有弹性的 DRL 库,其性能比 Stable Baseline 3 和 RLlib 更快更稳定。在三层架构部分,将详细解释 ElegantRL 如何在 FinRL 中完美地发挥其作用。如果您感兴趣,请参考 ElegantRL 的 GitHub 页面或文档。
借助这三个强大的 DRL 库,FinRL 为用户提供了以下算法

如介绍中所述,FinRL 的 DRL Agent 是由依赖于三个著名 DRL 库(ElegantRL、Stable Baseline 3 和 RLlib)的经过微调的标准 DRL 算法构建的。
支持的算法包括:DQN、DDPG、多 Agent DDPG、PPO、SAC、A2C 和 TD3。我们还允许用户通过调整这些 DRL 算法(例如,自适应 DDPG)或采用集成方法来设计他们自己的 DRL 算法。DRL 算法的比较如下表所示
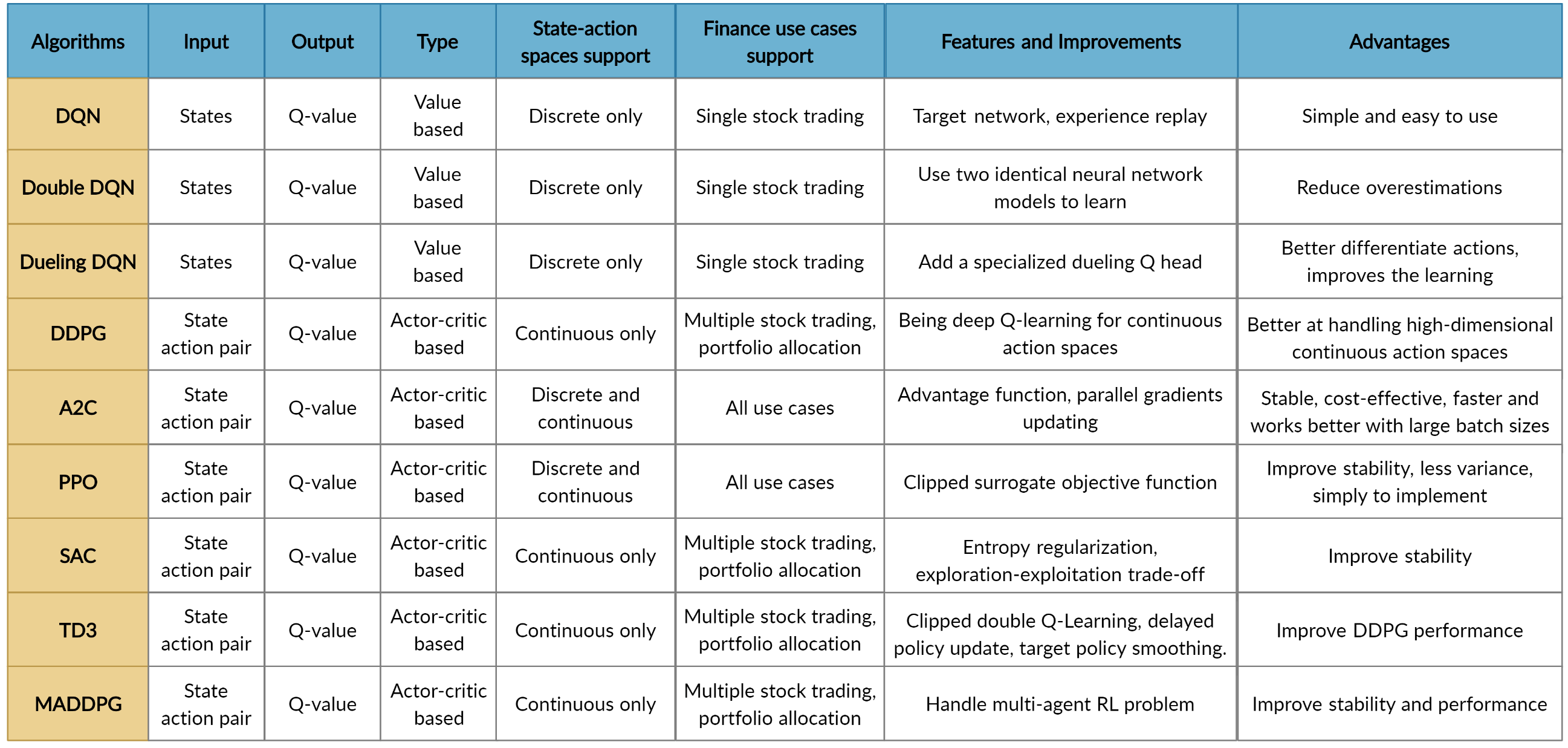
用户可以选择他们喜欢的 DRL Agent 进行训练。不同的 DRL Agent 在各种任务中可能有不同的表现。
ElegantRL: DRL 库¶
强化学习 (RL) 的一句话总结:在 RL 中,Agent 通过与未知环境持续交互,以试错的方式学习,在不确定性下做出序贯决策,并在探索(新领域)和利用(利用经验学到的知识)之间取得平衡。
深度强化学习 (DRL) 在解决对人类具有挑战性的现实问题方面具有巨大潜力,例如游戏、自然语言处理 (NLP)、自动驾驶汽车和金融交易。自 AlphaGo 成功以来,各种 DRL 算法和应用正以前所未有的方式涌现。ElegantRL 库使研究人员和从业者能够流水线化地实现 DRL 技术的颠覆性“设计、开发和部署”。
将要介绍的库在以下几个方面体现了“优雅”
轻量级:核心代码少于 1,000 行,例如 helloworld。
高效:性能与 Ray RLlib 相当。
稳定:比 Stable Baseline 3 更稳定。
ElegantRL 支持最先进的 DRL 算法,包括离散和连续算法,并在 Jupyter notebooks 中提供了用户友好的教程。ElegantRL 在 Actor-Critic 框架下实现了 DRL 算法,其中 Agent (也称为 DRL 算法) 由一个 Actor 网络和一个 Critic 网络组成。由于代码结构的完整性和简洁性,用户可以轻松定制自己的 Agent。