1. 股票市场环境¶
考虑到自动化股票交易任务的随机性和交互性,金融任务被建模为一个马尔可夫决策过程(MDP)问题。FinRL-Meta 首先对市场数据进行预处理,然后构建股票市场环境。环境观察股票价格和多种特征的变化,智能体采取行动并从环境中接收奖励,最后智能体相应地调整其策略。通过与环境互动,智能智能体将推导出一个交易策略,以最大化长期累积奖励(也称为 Q 值)。
我们的交易环境基于 OpenAI Gym,使用时间驱动模拟,利用真实市场数据来模拟市场。FinRL 库致力于提供由跨多个证券交易所的数据集构建的交易环境。
在教程和示例部分,我们将结合强化学习环境的组成部分来详细说明 MDP 的制定。
DRL 在金融领域的应用与其他领域(例如下棋和纸牌游戏)的应用不同;后者本身就具有明确定义的环境规则。各种金融市场需要不同的 DRL 算法才能获得最合适的自动化交易智能体。意识到设置训练环境是一项耗时且费力工作,FinRL 提供了基于代表性上市指数(包括 NASDAQ-100、DJIA、S&P 500、SSE 50、CSI 300 和 HSI)以及用户自定义环境的市场环境。因此,该库将用户从繁琐且耗时的数据预处理工作中解放出来。我们知道用户可能希望在自己的数据集上训练交易智能体。FinRL 库为用户导入的数据提供了便捷支持,并允许用户调整时间步长的粒度。我们指定了数据格式。根据我们的数据格式说明,用户只需预处理他们的数据集即可。
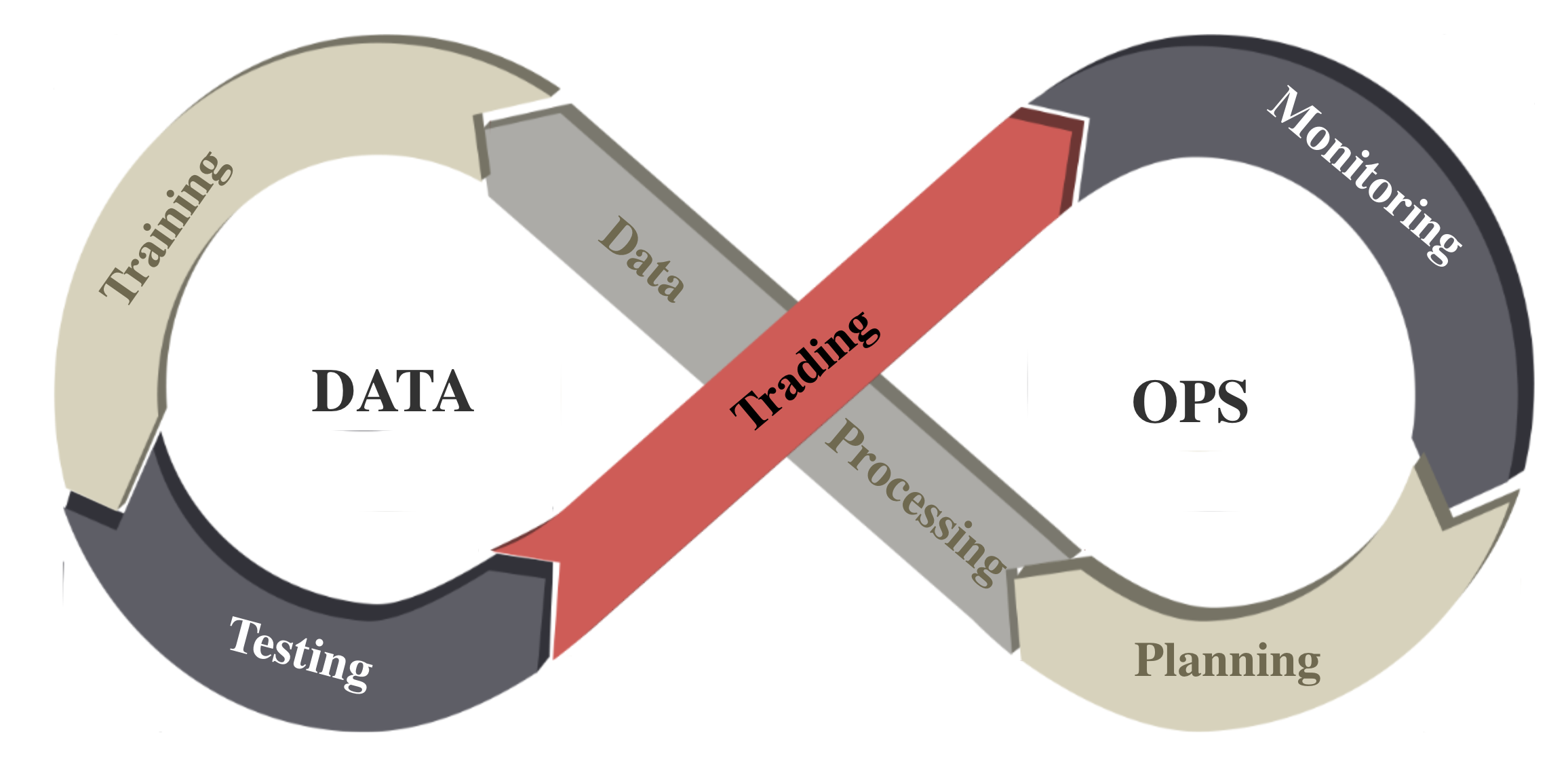
我们在数据层遵循 DataOps 范例。
我们为强化学习中的金融数据工程建立了一个标准流程,确保来自不同来源、不同格式的数据可以整合到一个统一的框架中。
我们使用数据处理器自动化此流程,该处理器可以高质量和高效率地访问、清理和提取各种数据源中的特征。我们的数据层为模型部署提供了敏捷性。
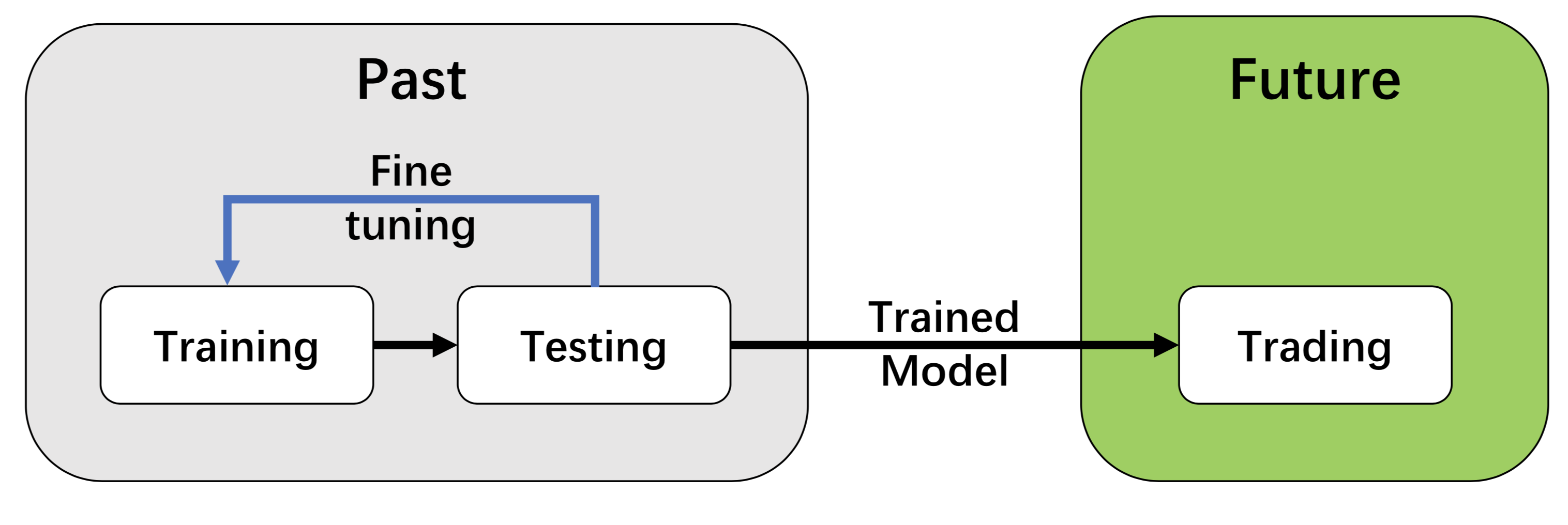
我们采用训练-测试-交易流程。DRL 智能体首先从训练环境中学习,然后在验证环境中进行验证以进行进一步调整。然后,经过验证的智能体在历史数据集上进行测试。最后,经过测试的智能体将被部署到模拟交易或实盘交易市场中。首先,此流程解决了信息泄露问题,因为在调整智能体时交易数据不会泄露。其次,统一的流程允许对不同算法和策略进行公平比较。
为了处理数据和构建金融领域 DRL 的环境,AI4Finance 维护了另一个项目:FinRL-Meta。